Transactional Outbox: reliable event publishing

Understand the Transactional Outbox pattern to publish events reliably from a transactional database, without dual writes
Transactional Outbox: reliable event publishing
Modern backends often mix two worlds:
- Transactional state (your database is the source of truth)
- Asynchronous communication (events are how services react and integrate)
That mix is powerful—and also where dual-write lives.
This article explains the Transactional Outbox pattern in a practical, backend-developer-friendly way. It uses a simple reference scenario (an Orders API writing to PostgreSQL and publishing events to a broker) and focuses on the conceptual flow rather than language-specific implementation.
Reference code for this article is available here: github.com/Pedrovinhas/transactional-outbox
Context and motivation: the dual-write problem
Imagine an Orders service that must do two things when a request arrives:
- Persist an
orderrow in the database - Publish an
order.createdevent so other services can react
If these two actions are not atomically coordinated, you get failure modes like:
- DB commit succeeds, publish fails → the order exists, but downstream never hears about it
- Publish succeeds, DB rolls back → an event exists for an order that doesn’t
- App crashes between steps → your system lands in an unknown state
Retries make it worse:
- Retrying the request might create duplicates
- Retrying event publishing might deliver the same event more than once
In short: your system becomes eventually inconsistent by accident, not by design.
What is the Transactional Outbox?
The Transactional Outbox pattern solves dual-write by changing where you write first.
Instead of writing to the database and the broker inside the request path, you:
- Write the business data (e.g.,
orders) - Also write an “event record” into an outbox table
- Do both in the same DB transaction
The outbox is a durable, queryable log of events that should be published.
A separate process (often called a relay, publisher, or outbox processor) reads pending outbox rows and publishes them to the message broker, marking them as published only after a successful publish.
Key idea:
You don’t try to make “DB + broker” atomic. You make “DB state + intent-to-publish” atomic.
How it works: conceptual flow
Here’s the conceptual lifecycle of an event.

1) Write state and outbox in one transaction
When the API handles POST /orders:
- Begin a DB transaction
- Insert the order
- Insert a new outbox row representing the event (
order.created, payload, metadata) - Commit
If the transaction commits, you now have:
- The order persisted
- A durable record that an event must be published
If it rolls back, you have neither.
2) Relay publishes outbox rows
A relay process continuously (or periodically) reads outbox rows where published = false:
- Publishes the event to the broker (e.g., RabbitMQ exchange)
- On broker ACK, updates the outbox row (
published=true,published_at=now()) - On failure, retries later
This can be done with polling, CDC, or other mechanisms. Polling is common in PoCs and small systems because it’s simple and reliable.
3) Consumers handle duplicates
Even with a relay, at-least-once delivery is still the default reality in distributed systems:
- The relay might publish, crash before marking
published=true, then publish again - The broker might redeliver after consumer failure
So consumers should be idempotent, or you introduce a complementary pattern: Inbox.
Inbox: durable receive + idempotent processing
An Inbox is a table that stores received event IDs and processing status.
Typical flow:
- Consumer receives message
- Persist message into
inbox(unique constraint on event ID) - ACK the broker
- A separate processor reads unprocessed inbox rows and runs business side effects
This gives you:
- Deduplication / idempotency
- Traceability: what was received and what was processed
- Controlled retries for business logic
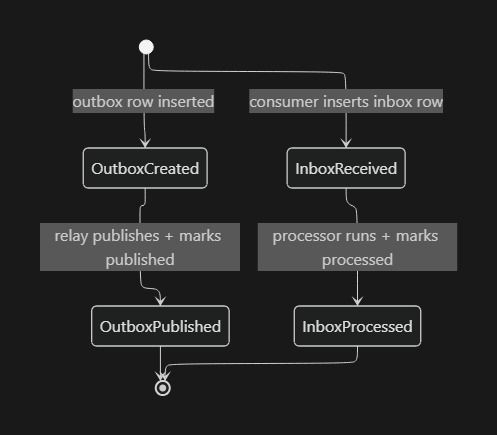
You can think about both tables as simple state machines:
Observability is required
Transactional Outbox makes failures recoverable, but only if you can see them. In real systems, a “stuck outbox” or “growing inbox backlog” is a production incident waiting to happen.
At minimum, plan for:
- Backlog metrics: count of pending outbox rows, unprocessed inbox rows
- Lag/age metrics: oldest unpublished outbox event age, oldest unprocessed inbox event age
- Throughput: publish rate, consume rate, processing rate
- Retries and failures: publish errors, consumer insert conflicts (dedupe hits), processing failures
- Tracing and correlation: propagate correlation IDs and emit spans from API → relay → consumer → processor (e.g., OpenTelemetry + Jaeger)
If you can’t monitor these signals, you can’t tell whether your system is “eventually consistent” or “quietly broken.”
Benefits and trade-offs
Benefits
- No more accidental inconsistency from dual-write
- Stronger reliability: once the DB transaction commits, the event won’t be “lost”
- Operational visibility: outbox/inbox tables become an audit trail
- Graceful recovery: failures become “pending rows to retry” instead of mystery bugs
Trade-offs
- Event publishing is asynchronous: there is always some latency
- More moving parts: relay process, scheduling, monitoring, backoff strategies
- At-least-once semantics: you must design for duplicates
- Operational load: indexes, cleanup/retention policies, and throughput planning
When to use (and when to avoid)
Use Transactional Outbox when
- You have a transactional database as your system of record
- You need reliable integration events (billing, notifications, downstream workflows)
- You operate microservices and can tolerate eventual consistency
- You want reproducible, inspectable failure recovery (retries from tables)
Avoid or reconsider when
- You truly need strong consistency across services (rare; usually indicates wrong boundaries)
- Your domain can’t accept any delay between write and publish
- You can’t invest in idempotency (duplicates would be catastrophic)
- Your architecture is better served by a different approach (e.g., CDC with Debezium at scale)
Relationship to event-driven architectures
Transactional Outbox is not “event-driven architecture by itself”—it’s a bridge between:
- A database transaction (local consistency)
- A broker-based event stream (distributed coordination)
It lets you adopt event-driven integration incrementally:
- Your service remains the owner of its data
- You publish integration events reliably
- Other services react asynchronously
Also note the difference between brokers:
- A message broker like RabbitMQ is great for delivery, but it is not an event log by default
- If you need replay, long-term retention, and stream processing, systems like Kafka might be a better fit
Conclusion
The Transactional Outbox pattern is one of the most pragmatic tools for backend teams building reliable, event-driven systems on top of transactional databases.
It doesn’t magically remove distributed systems complexity—but it moves complexity into a place you can control:
- a transactionally consistent write
- a durable outbox
- a relay that can retry
- consumers built for idempotency (often with an inbox)
If you’re currently publishing events “right after commit” and hoping nothing fails in between, Transactional Outbox is the upgrade that turns hope into an engineering guarantee.